InworldLLMModule | Inherits from: InworldFrameworkModule
Module for Large Language Model (LLM) integration in the Inworld framework. Provides text generation capabilities using both remote and local AI models.
Properties
- Provider
- ModelName
- ModelPath
- MaxToken
- MaxPromptLength
- Repetition
- Temperature
- TopP
- Frequency
- Presence
Methods
Reference
Provider
Gets or sets the AI model provider (e.g., OpenAI, Anthropic). Used when connecting to remote LLM services.Returns
Type:string
Description: The provider name as a string.
ModelName
Gets or sets the specific model name to use for text generation. This should correspond to models available from the configured provider.Returns
Type:string
Description: The model name as a string.
ModelPath
Gets or sets the file path to a local LLM model. If not set, defaults to the framework’s default LLM model path.Returns
Type:string
Description: The full file path to the local model.
MaxToken
Gets or sets the maximum number of tokens the model can generate in a single response. Value is automatically clamped between 1 and 2500.Returns
Type:int
Description: The maximum token count (1-2500).
MaxPromptLength
Gets or sets the maximum length of the input prompt in tokens. Value is automatically clamped between 1 and 2500.Returns
Type:int
Description: The maximum prompt length (1-2500).
Repetition
Gets or sets the repetition penalty factor. Higher values reduce the likelihood of repeating the same content. Value is automatically clamped between 0 and 1.Returns
Type:float
Description: The repetition penalty (0.0-1.0).
Temperature
Gets or sets the temperature for text generation. Higher values produce more creative/random output, lower values are more focused. Value is automatically clamped between 0 and 1.Returns
Type:float
Description: The temperature value (0.0-1.0).
TopP
Gets or sets the top-p (nucleus sampling) parameter. Controls diversity by only considering tokens with cumulative probability up to this value. Value is automatically clamped between 0 and 1.Returns
Type:float
Description: The top-p value (0.0-1.0).
Frequency
Gets or sets the frequency penalty factor. Reduces the likelihood of repeating frequently used tokens. Value is automatically clamped between 0 and 1.Returns
Type:float
Description: The frequency penalty (0.0-1.0).
Presence
Gets or sets the presence penalty factor. Encourages the model to talk about new topics by penalizing tokens that have already appeared. Value is automatically clamped between 0 and 1.Returns
Type:float
Description: The presence penalty (0.0-1.0).
GenerateText
Generates text synchronously using the configured LLM. This method blocks until the generation is complete.Parameters
| Parameter | Type | Description |
|---|---|---|
| text | string | The input text prompt for generation. |
Returns
Type:string
Description: The generated text response, or empty string if generation fails.
GenerateTextAsync
Generates text asynchronously using the configured LLM. This method performs generation on a background thread for improved performance.Parameters
| Parameter | Type | Description |
|---|---|---|
| text | string | The input text prompt for generation. |
Returns
Type:Awaitable<string>
Description: A task that completes with the generated text response, or empty string if generation fails.
SetupTextGenerationConfig
Sets up and returns a text generation configuration instance based on current module settings. This method configures all text generation parameters including token limits, penalties, and sampling parameters.Returns
Type:TextGenerationConfig
Description: A configuration instance for text generation with current module settings.
Serialized Fields
The following fields are configurable in the Unity Inspector:Remote Configuration
- m_Provider (
string) - The AI model provider (e.g., OpenAI, Anthropic) - m_ModelName (
string) - The specific model name to use for text generation
Local Configuration
- m_ModelPath (
string) - The file path to a local LLM model
Text Configuration
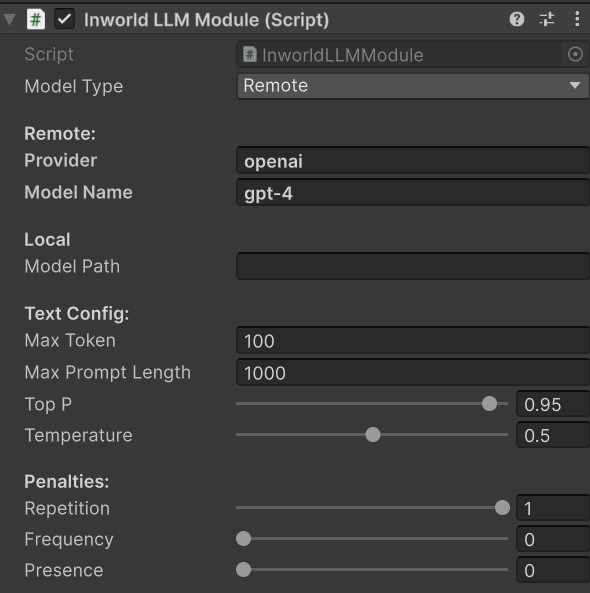
- m_MaxToken (
int) - Maximum number of tokens to generate (default: 100, range: 1-2500) - m_MaxPromptLength (
int) - Maximum length of input prompt in tokens (default: 1000, range: 1-2500) - m_TopP (
float) - Top-p (nucleus sampling) parameter (default: 0.95, range: 0-1) - m_Temperature (
float) - Temperature for text generation (default: 0.5, range: 0-1)
Penalty Configuration
- m_Repetition (
float) - Repetition penalty factor (default: 1.0, range: 0-1) - m_Frequency (
float) - Frequency penalty factor (default: 0.0, range: 0-1) - m_Presence (
float) - Presence penalty factor (default: 0.0, range: 0-1)
Configuration Management
Remote Configuration
When using remote models, the module creates anLLMRemoteConfig with:
- Provider name (if specified)
- Model name (if specified)
- API key from framework utilities
Local Configuration
When using local models, the module creates anLLMLocalConfig with:
- Model path (resolved from StreamingAssets folder)
- Device configuration from framework utilities
Text Generation Configuration
TheSetupTextGenerationConfig() method configures:
- Maximum token count
- Repetition penalty
- Top-p and temperature (with GPT-5 compatibility handling)
- Maximum prompt length
- Frequency and presence penalties