- Configure multiple named instances of each primitive type (LLM, STT, TTS, Text Embedder)
- Set up provider-specific configurations (Inworld, OpenAI, Anthropic, Google, etc.)
- Define reusable configurations that can be referenced by nodes in your graphs
- Easily access and modify your primitives across your project
Accessing Primitives Configuration
To configure primitives in your project:- Open Edit > Project Settings from the main menu
- Navigate to Plugins > Inworld in the left sidebar
- Scroll down to the Primitives section
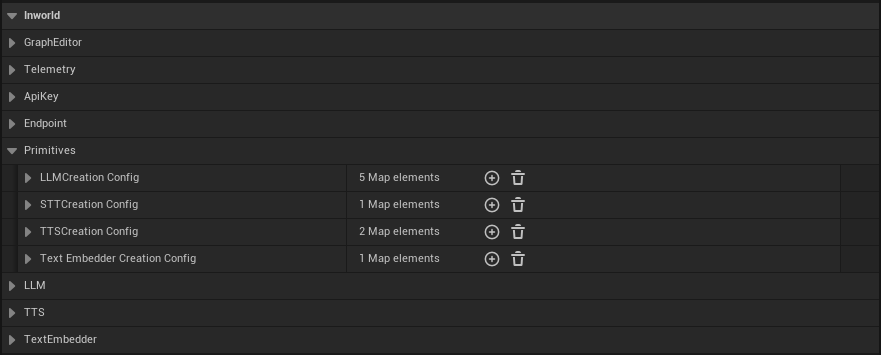
- LLM Creation Config - Configure Large Language Models
- STT Creation Config - Configure Speech-to-Text models
- Streaming STT Creation Config - Configure real-time streaming Speech-to-Text models
- TTS Creation Config - Configure Text-to-Speech models
- Text Embedder Creation Config - Configure text embedding models
LLM
LLMs are powerful models that can be used to understand and generate text and other content. To configure an LLM: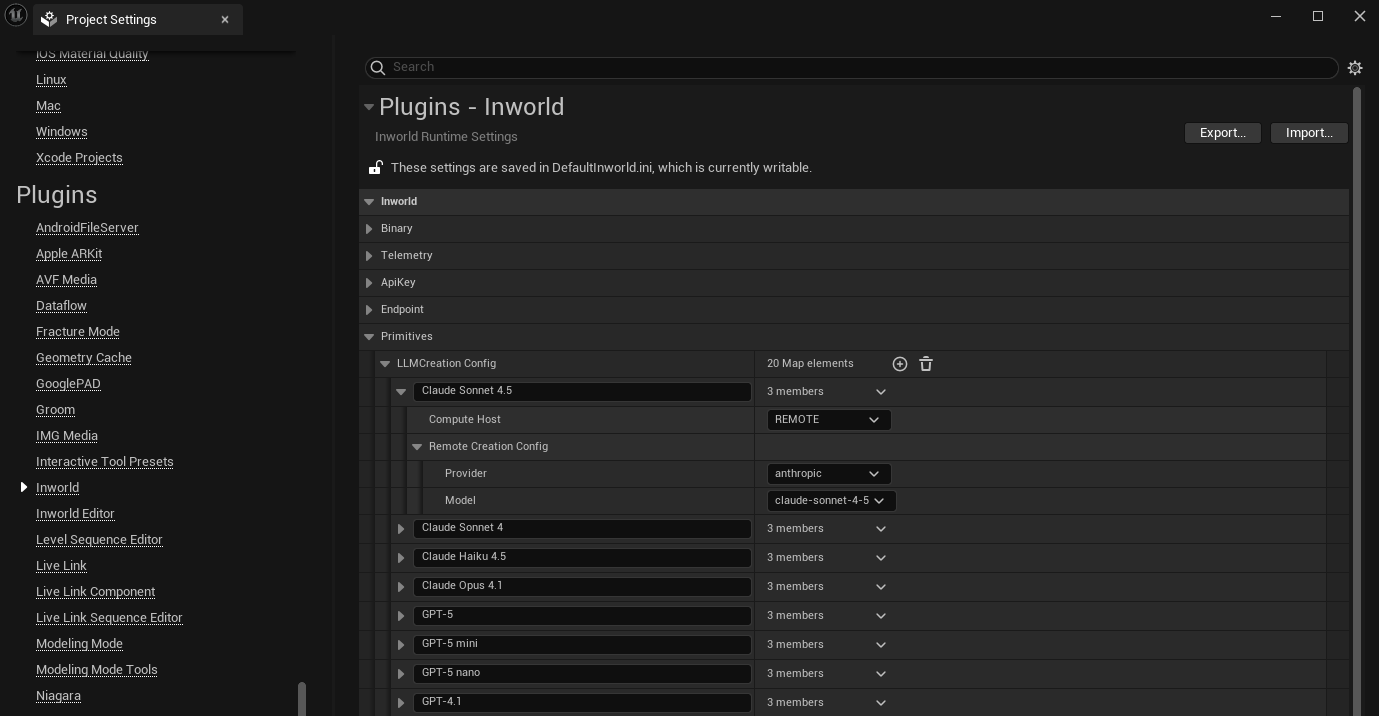
- In the LLM Creation Config map, click the + button to add a new entry
- Set a descriptive name for this configuration. This name will be used for selecting this configuration in your graph.
-
Select either
LocalorRemotefor the Compute Host- Remote: this means that the models will be run by cloud servers.
- Provider: Select from available service providers.
- Model: Choose the specific model. Make sure you specify a model that is provided by the selected provider. See Adding models or providers.
- Local: this means that the models will run locally
- Local Compute Host: Choose
CPUorGPU - Model: Path to the local model.
- Local Compute Host: Choose
- Remote: this means that the models will be run by cloud servers.
- Your configuration will now be available for selection in LLM powered nodes throughout your graphs.
Adding models or providers
All service providers and models listed under Chat Completion are supported. If a model or service provider is not available in the Remote LLM Creation Config dropdown, you can add additional options under the LLM section of the Inworld Agent Runtime Settings.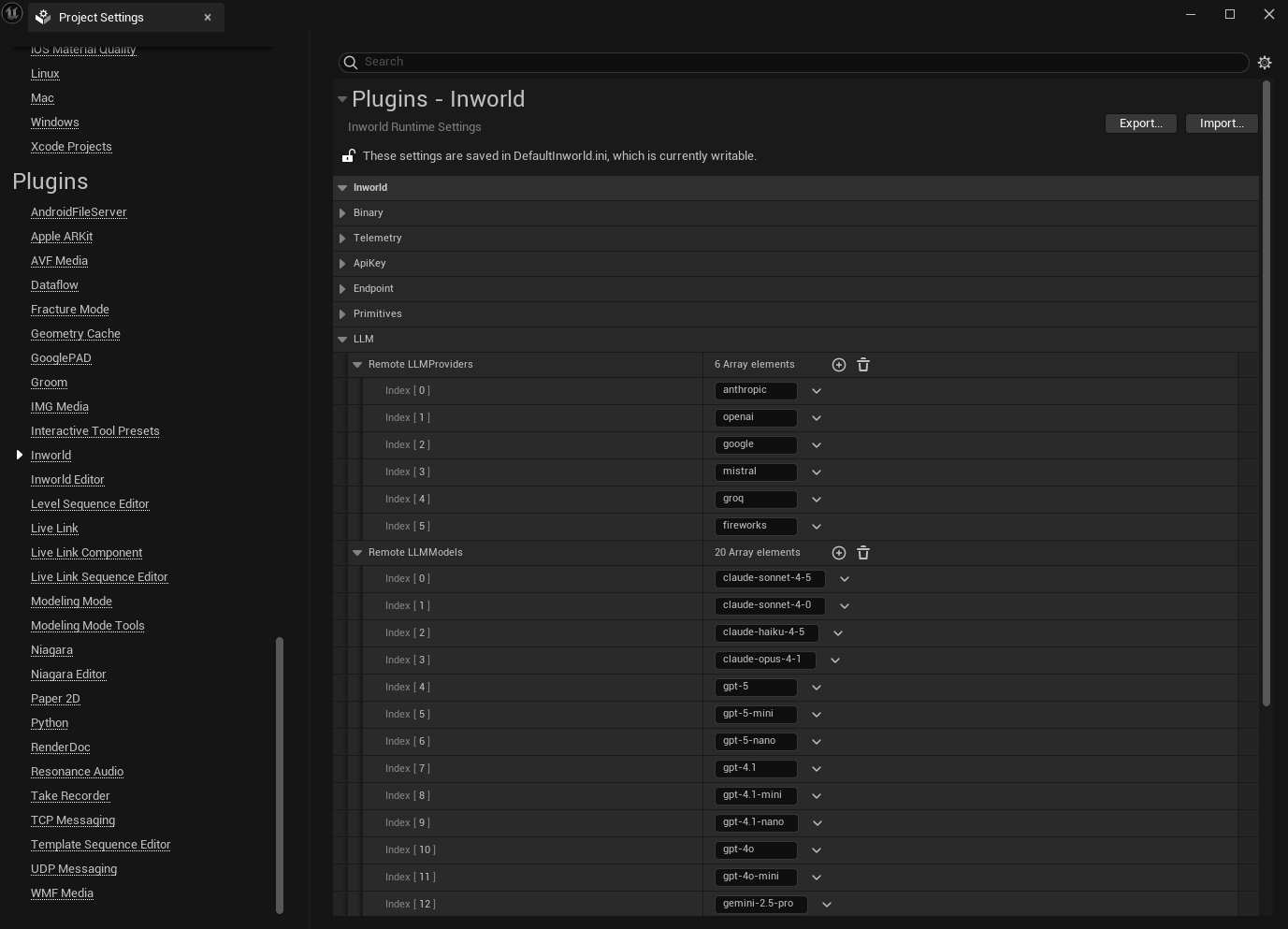
- In the Remote LLMProviders list, click the + button to add any additional service providers you want to use.
- In the Remote LLMModels list, click the + button to add any additional models you want to use.
TTS
Text-to-Speech converts text into audio. To configure TTS:- In the TTS Creation Config map, click the + button to add a new entry
- Set a descriptive name for this configuration. This name will be used for selecting this configuration in your graph.
- Select either
LocalorRemotefor the Compute Host-
Remote: this means that the models will be run by cloud servers.
- Provider: Select
INWORLD - Configure provider-specific settings like model selection and voice parameters.
- Provider: Select
-
Local: this means that the models will run locally
- Local Compute Host: Choose
CPUorGPU - Model: Path to the local model.
- Speech Synthesis Config: Adjust parameters like sample rate, temperature, and speaking rate.
- Local Compute Host: Choose
-
Remote: this means that the models will be run by cloud servers.
- Your configuration will now be available for selection in TTS nodes throughout your graphs.
STT
Speech-to-Text converts a complete audio clip into text. Use this for pre-recorded audio. For live microphone input, see Streaming STT below. To configure STT:- In the STT Creation Config map, click the + button to add a new entry
- Set a descriptive name for this configuration. This name will be referenced by the STT Component ID field on STT nodes.
- Select either
LocalorRemotefor the Compute Host- Remote: models run on cloud servers.
- Service: Choose from available providers:
- Inworld — routes through Inworld’s STT API. Set a Model ID (e.g.
groq/whisper-large-v3) and optionally an Endpoint Override and Default Timeout. - Groq — calls Groq’s transcription API directly. Set a Model ID (e.g.
whisper-large-v3) and optionally a Default Timeout.
- Inworld — routes through Inworld’s STT API. Set a Model ID (e.g.
- Both providers support a Language setting for improved recognition accuracy.
- Service: Choose from available providers:
- Local: models run on-device.
- Local Compute Host: Choose
CPUorGPU - Model: Path to the local model file.
- Local Compute Host: Choose
- Remote: models run on cloud servers.
- Your configuration will now be available for selection in STT nodes throughout your graphs.
Streaming STT
Streaming Speech-to-Text transcribes audio incrementally in real-time as it arrives, making it suitable for live microphone input. Use this with STT nodes that have Streamed enabled and receiveFInworldData_DataStream_AudioChunk input.
To configure Streaming STT:
- In the Streaming STT Creation Config map, click the + button to add a new entry
- Set a descriptive name for this configuration. This name will be referenced by the Streaming STT Component ID field on STT nodes.
- Select either
LocalorRemotefor the Compute Host- Remote: models run on cloud servers.
- Model ID: The streaming model to use (default:
assemblyai/universal-streaming-multilingual). - Silence Threshold (ms): Duration of silence in milliseconds before speech is considered ended (default:
1500). - Activity Detection (optional): Fine-tune end-of-turn detection with per-provider settings:
- End of Turn Confidence Threshold — confidence required to commit a turn boundary.
- Min End of Turn Silence When Confident — minimum silence when confidence is high (ms).
- Max Turn Silence — maximum silence before forcing a turn boundary (ms).
- Endpoint Override (optional): Override the default service endpoint.
- Default Timeout (optional): Request timeout in seconds.
0means no timeout.
- Model ID: The streaming model to use (default:
- Local: models run on-device. Requires separate model and device selection for both the STT and VAD components:
- STT Local Compute Host / STT Model: Device and model path for speech recognition.
- VAD Local Compute Host / VAD Model: Device and model path for voice activity detection.
- Silence Threshold (ms): Same as remote — duration of silence before speech ends.
- Remote: models run on cloud servers.
- Your configuration will now be available for selection in STT nodes that have Streamed enabled.
Text Embedder
Text Embedders convert text into numerical vectors for semantic operations, and powers features like intent detection and knowledge retrieval. To configure embedders:- In the Text Embedder Creation Config map, click the + button to add a new entry
- Set a descriptive name for this configuration. This name will be used for selecting this configuration in your graph.
- Select either
LocalorRemotefor the Compute Host-
Remote: this means that the models will be run by cloud servers.
- Provider: Select from available providers
- Model: Choose the embedding model
-
Local: this means that the models will run locally
- Local Compute Host: Choose
CPUorGPU - Model: Path to the local model.
- Local Compute Host: Choose
-
Remote: this means that the models will be run by cloud servers.
- Your configuration will now be available for selection in embeddings powered nodes throughout your graphs.