LLM
Getting Started
To get started with the Inworld Unreal Engine SDK LLM, refer to the sections below.
Obtain Runtime API Key
All requests to the Inworld LLM Service API must include both a Runtime API Key and a unique User Id.
To obtain a Runtime API key, perform the following steps:
- Navigate to Inworld Studio.
- From within a studio workspace, navigate to the Integrations tab.
- Go to the Runtime API Key section and click Generate new key.
- Click the Base 64 to copy the key for use.
Project Settings
From the Unreal Editor, navigate to: Edit > Project Settings > Plugins > InworldAI - LLM
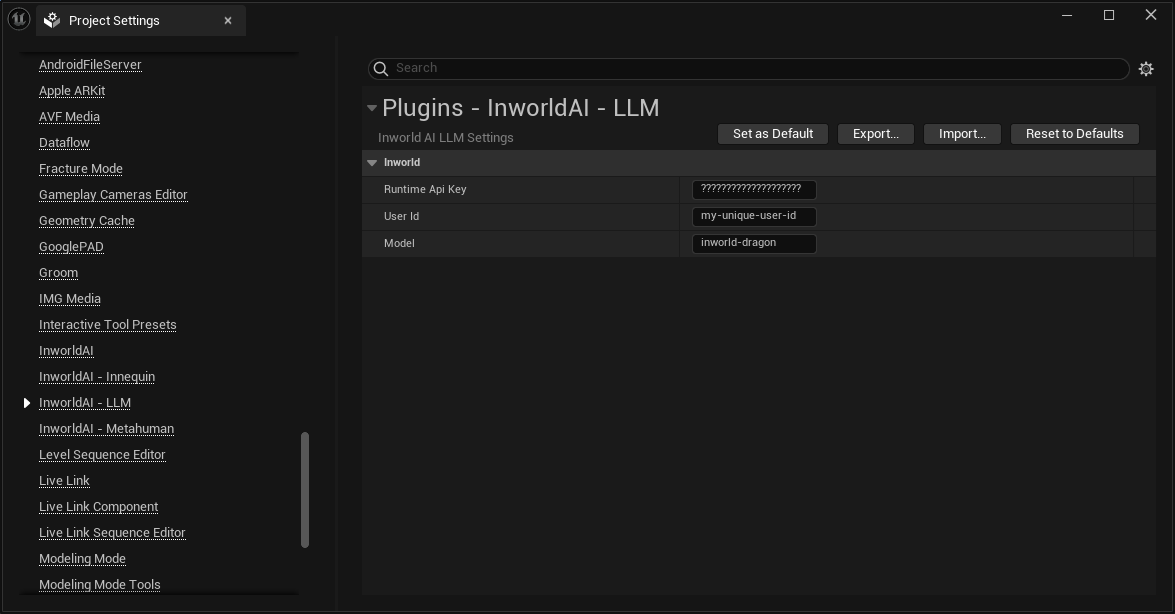
ApiKey - The Base64 authorization signature copied from Studio. User Id - Unique identifier for the end-user associated with the request. Model Id - ID of the model to use. Options include inworld-pixie (small model) and inworld-dragon (large model).
Note: The values set here specify a default. These values can be overridden per blueprint node.
Completion Events
Below are the provided methods of completion using the LLM Service.
Each completion event utilizes a Text Generation Config with the following properties:
- Max Tokens - Maximum number of output tokens to generate.
- Temperature - Determines randomness of response. Higher values result in greater randomness.
- Presence Penalty - Positive values penalize new tokens based on whether they appear in the generated text so far, increasing the model's likelihood to talk about new topics.
- Repetition Penalty - Penalizes new tokens based on whether they appear in the prompt and the generated text so far. Values greater than 1 encourage the model to use new tokens, while values less than 1 encourage the model to repeat tokens. The value must be strictly positive.
- Frequency Penalty - Positive values penalize new tokens based on their existing frequency in the generated text so far, decreasing the model's likelihood to repeat the same line verbatim.
- Top P - Use nucleus sampling, where the model only considers the results of the tokens with Top P probability mass. For example, 0.1 means only the tokens comprising the top 10% probability mass are considered. It is generally recommended to either alter temperature of top p, but not both.
- Stream - Wether or not to stream responses.
Complete Text
Generate a text response for a provided prompt.
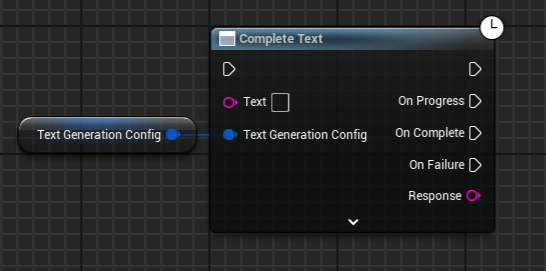
Text - Prompt to generate the text.
Text Generation Config - Configuration for generating text (see above).
Complete Chat
Generate a chat completion.
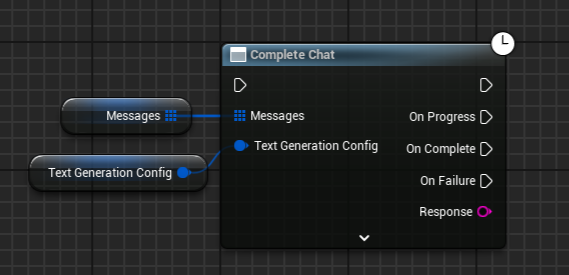
Messages - An array of messages that form the conversation history. Each message includes an author role, and the content of the message.
Text Generation Config - Configuration for generating text (see above).